Stack
in CS on Data Structure
Stack
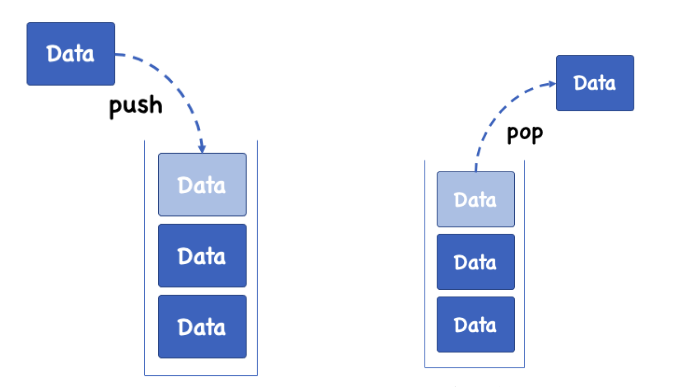
LIFO (Last In First Out)
마지막에 들어온 데이터가 가정 먼저 나오는 특징을 가지고 있다.
실사용 예시로 컴퓨터를 종료하게 되면 먼저 실행했던 프로세스들이 꺼지고, 마지막에 OS가 꺼진다.
메서드
삽입 (Push)
Push는 스택의 구조상 최상 위에 데이터가 저장 된다.
삭제 (Pop)
Push와 반대로 데이터를 삭제하는 것을 Pop이라 한다.
Pop도 Push와 마찬가지로 최상위 데이터 위치에서 삭제가 됩니다.
읽기 (Peek)
마지막 위치(top)에 해당하는 데이터를 읽습니다. 이 때, top의 변화는 없습니다.
구현
루트 폴더에서 특정 폴더까지의 경로를 찾는 과정에서 사용하게 됐다.
// XxxController
@Override
public FileManageDto getDirFileList(String dataSeq) {
Stack<FileManageDto> fileManageDtoStack = driveMapper.recursiveQuery(dataSeq);
Collections.reverse(fileManageDtoStack);
return recursiveMethod(fileManageDtoStack);
}
// 스택을 활용한 재귀함수 구현.
public FileManageDto recursiveMethod(Stack<FileManageDto> fileManageList) {
FileManageDto lastObject = fileManageList.get(fileManageList.size() - 1);
FileManageDto beforeLastObject = fileManageList.get(fileManageList.size() - 2);
fileManageList.get(lastObject).setChildFolder(beforeLastObject);
fileManageList.pop();
if (fileManageList.size() > 1) {
recursiveMethod(fileManageList); // 재귀
}
return fileManageList.get(0);
}
자바에서는 java.util.Stack 클래스를 사용해서 구현하면된다.
아래 이미지는 Stack의 상속관계도를 나타낸 그림이다.
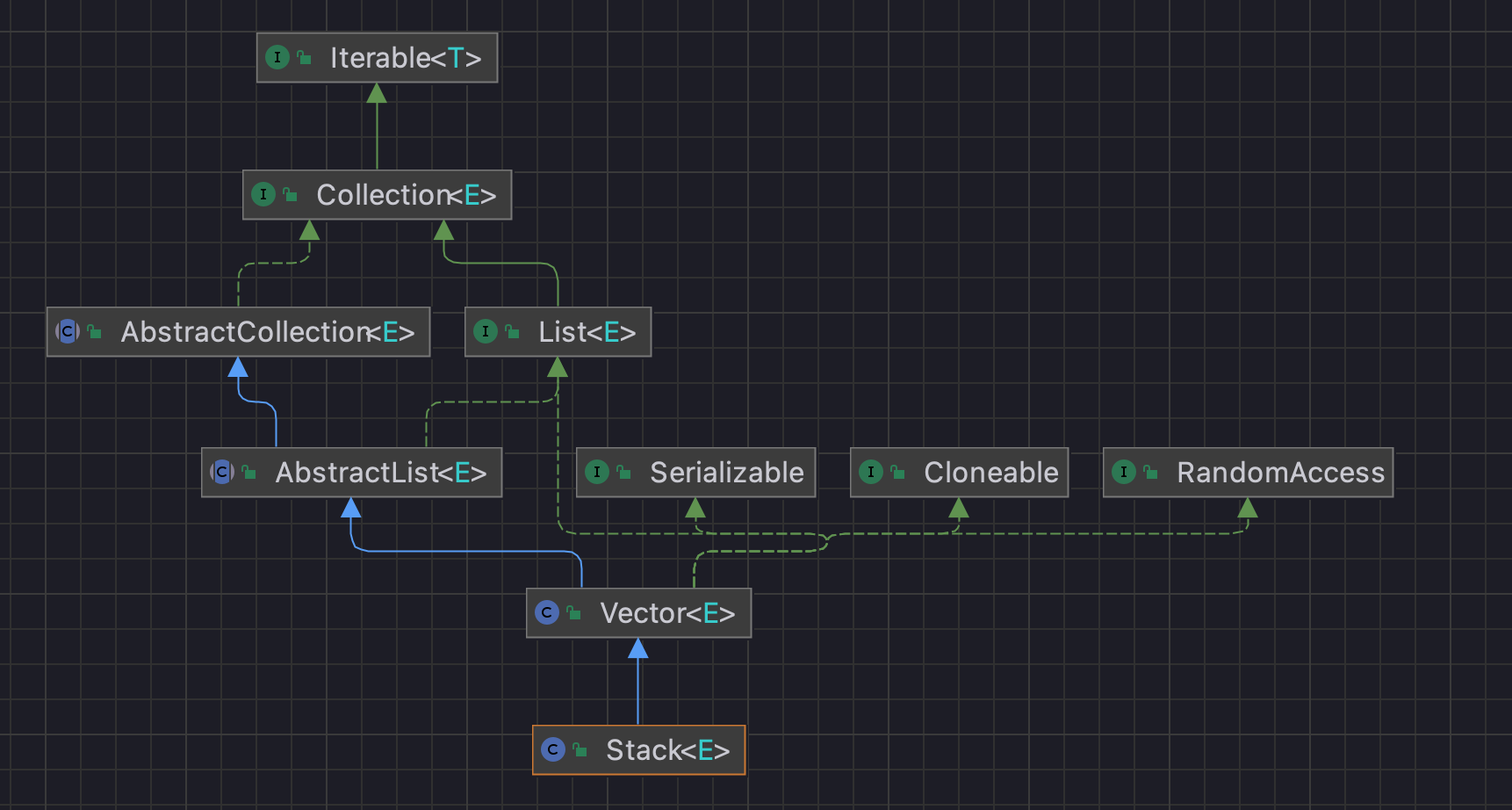
위 이미지에서 확일할 수 있듯 List 인터페이스를 통해서 구현이 충분히 가능한 코드이다.
하지만 여기서 Stack을 사용한 이유는 마지막 데이터를 삭제할 때 시간복잡도를 줄여보고 싶어서였다.
재귀함수를 써서 최대한 복잡도를 줄여보고 싶었음.
일반 ArrayList의 경우 데이터를 삭제할 때 최악의 경우 O(N) 의 시간 복잡도를 가진다.
반면에 Stack의 경우에는 최상단에서만 데이터의 이동이 일어나기 때문에 어떤 경우에도
O(1) 의 시간 복잡도를 가진다. (Linked List도 마찬가지이다.)
느낀점
사실 매번 자료구조를 공부하면서 “이걸 실무에서 어떤 경우에 적용하지?” 라는 의문을
품고 있었는데, 실제 프로젝트에서 구현해보니깐 자료구조의 중요성이 더 크게 다가왔다.
