로드 밸런싱
트래픽
트래픽이란?
트래픽이란 서버와 스위치 등 네트워크 장치에서 일정 시간 내에 흐르는 데이터의
양을 말한다. 웹 사이트에 트래픽이 많다는 것은 사용자 접속이 많아서 전송하는
데이터의 양이 많다는 것을 뜻한다.
트래픽이 너무 많으면 서버에 과부하가 걸려서 기능에 문제가 생길수 있다.
교통이나 운수 분야에서 사용하는 교통량(Traffic)이라는 용어와 구별하기 위해
웹 트래픽(Web Traffic) 또는 네트워크 트래픽(NetWork Traffic)이라고도 한다.
로드 밸런서
로드 밸런서란?
로드 밸런서는 서버에 가해지는 부하(Load)를 분산(Blancing) 해주는 장치 또는
기술을 통칭한다. 클라이언트와 서버풀(Server Pool) 사이에 위치하며, 한 대의
Server Pool : 분산 네트워크를 구성하는 서버들의 그룹
서버로 부하가 집중되지 않도록 트래픽을 관리해 각각의 서버가 최적의 퍼포먼스를
보일 수 있도록 한다.
로드 밸런싱
로드 밸런싱이란?
분산부하 또는 로드 밸런싱은 컴퓨터 네트워크 기술의 일종으로 둘 혹은 셋 이상의
컴퓨터 자원들에게 작업을 나누는 것을 의미한다.
즉, 외부로부터의 요청을 서버가 직접 받는 것이 아닌 Network-Switch 혹은 소프트웨어가
받은 후 이를 서버로 적절히 나누어 주는 것이다. 그리고 이 서버 부하 분산을 담장하는
Network Switch를 L4/L7 Switch 라고 부른다.
트래픽 대처 방법
| 방법 | 설명 |
|---|---|
| Scale-Up | 서버 자체의 성능을 확장하는 것. |
| Scale-Out | 기존 서버와 동일하거나 낮은 성능의 서버를 두 대 이상 증설하여 운영하는 것. |
만약 트래픽을 감당하기 위해서 scale-out 방식을 사용하기로 했다면,
여러 대의 서버로 트래픽을 균등하게 분산해주는 로드 밸런싱이 반드시 필요하다.
로드 밸런싱 알고리즘
라운드 로빈(Round Robin)
서버에 들어온 요청을 순서대로 돌아가며 배정하는 방식이다. 클라이언트의 순서대로
분배하기 때문에 여러 대의 서버가 동일한 스펙을 갖고 있고, 서버와의 연결이 오래
지속되지 않는 경우에 활용하기 적합하다.
스케쥴링에서도 사용되는 알고리즘
가중 라운드로빈(Weighted Round Robin)
각각의 서버마다 가중치를 매기고 가중치가 높은 서버에 클라이언트 요청을 우선적으로
배분한다. 주로 서버의 트래픽 처리 능력이 상이한 경우 사용되는 부하 분산 방식이다.
예를 들어 A라는 서버가 5라는 가중치를 가지고 있고, B라는 서버가 2라는 가중치를
갖는다면, 로드 밸런서는 라운드로빈 방식으로 A서버에 5개, B서버에 2개의 요청을 전달한다.
IP 해시(IP Hash)
클라이언트의 IP주소를 특정 서버로 매핑하여 요청을 처리하는 방식이다. 사용자의 IP를
해싱해 로드를 분배하기 때문에 사용자가 항상 동일한 서버로 연결되는 것을 보장한다.
최소 연결 방식(Least Connection Method)
로드밸런서가 서버에게 요청을 전달한 뒤, 사용자와 서버가 정상적인 연결을 맺으면 사용자와
서버는 Connection을 생성한다. 로드밸런서 또한 중간자로서 Connection 정보를 갖고 있는데
이 Connection 수 정보를 기반으로 가장 Connection이 적은 서버, 즉 부하가 가장 덜한 서버에게
요청을 전달한다.
최소 리스폰타임(Least Response Time)
서버의 현재 연결 상태와 응답시간을 모두 고려하여 트래픽을 배분한다. 가장 적은 연결 상태와
가장 짧은 응답시간을 보이는 서버에 우선적으로 부하를 배분하는 방식이다.
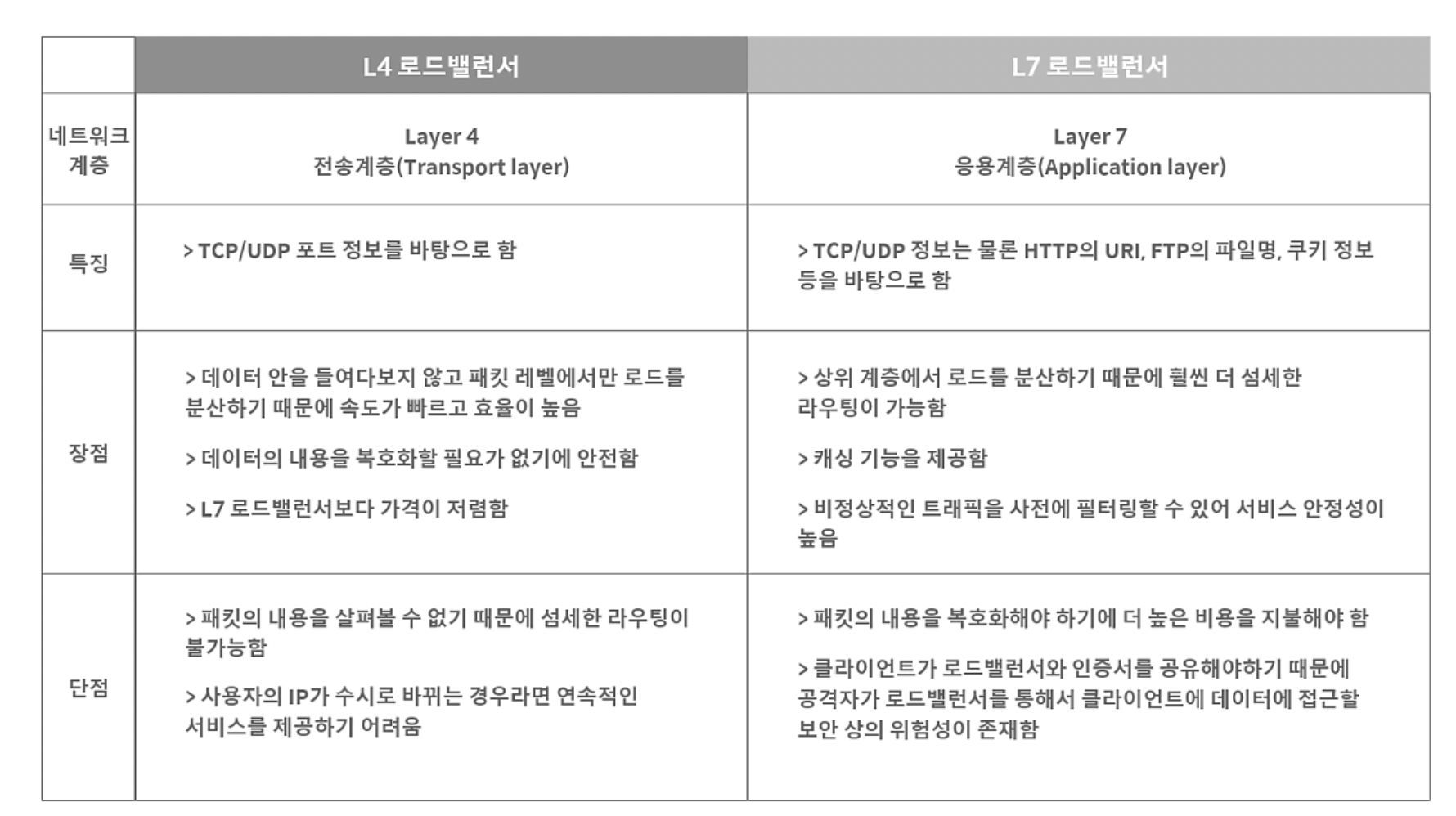
L4 로드밸런싱과 L7 로드밸런싱
부하 분산에서는 L4,L7 로드벨런서가 가장 많이 활용된다.
우선 L4 로드 밸런서는 네크워크 계층이나 전송 계층의 정보를 바탕으로 로드를 분산한다.
IP주소나 포트번호, MAC 주소, 전송 프로토콜에 따라 트래픽을 나누는 것이 가능하다.
한 대의 서버에 각기 다른 포트 번호를 부여하여 다수의 서버 프로그램을 운영하는 경우라면
최소 L4 로드벨런서 이상을 사용해야 한다.
반면 L7 로드 밸런서의 경우 응용계층에서 부하를 분산하기 때문에 HTTP 헤더, 쿠키 등과 같은
사용자의 요청을 기준으로 특정 서버에 트래픽을 분산 하는 것이 가능하다.
쉽게 말해 페킷의 내용을 확인하고 그 내용에 따라 부하를 특정 서버에 분산하는 것이 가능하다.
또한 특정한 패턴을 지닌 바이러스를 감지해 네트워크를 보호할 수 있으며 Dos/DDoS와
같은 비정상적인 트래픽을 필터링할 수 있어 네트워크 보안 분야에서도 활용되고 있다.