인공신경망(ANN)
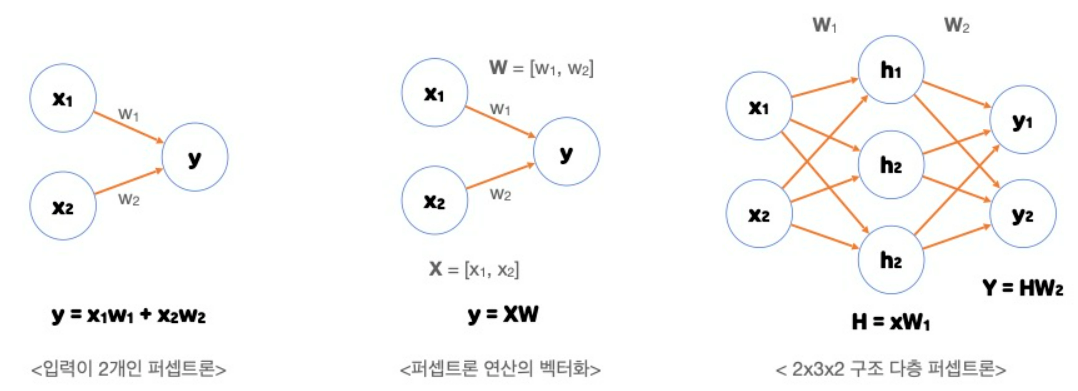
💡 Perceptron
퍼셉트론(Perceptron)은 프랑크 로젠블라트(Frank Rosenblatt)가 1957년에
제안한 초기 형태의 인공 신경망으로 다수의 입력으로부터 하나의 결과를
내보내는 알고리즘이다.
💡 입력층, 은닉층, 출력층
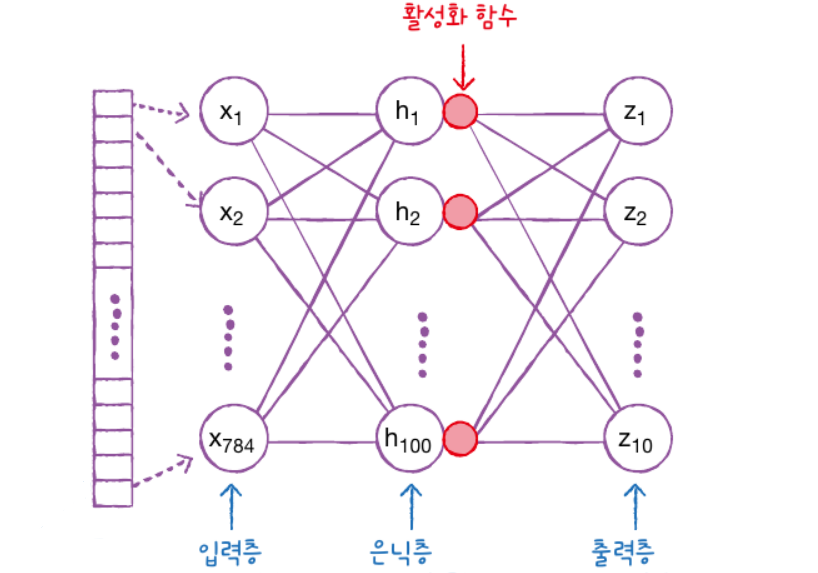
1. 입력층
입력층은 데이터셋이 입력되는 층입니다. 입력되는 데이터셋의 특성(Feature)에
따라 입력층 노드의 수가 결정됩니다. 보통 입력층은 어떤 계산도 수행하지 않고
그냥 값들을 전달하기만 하는 특징을 가지고 있습니다.
그렇기 때문에 신경망의 층수(깊이, depth)를 셀 때 입력층은 포함하지 않습니다.
2. 은닉층
은닉층은 입력층으로부터 입력된 신호가 가중치, 편향과 연산되는 층입니다.
일반적으로 입력층과 출력층 사이에 있는 층을 은닉층이라고 부릅니다.
은닉층에서 일어나는 계산의 결과를 사용자가 볼 수 없기 때문에 ‘은닉(Hidden)층’
이라는 이름이 붙었습니다.
은닉층은 입력 데이터셋의 특성 수와 상관 없이 노드 수를 구성할 수 있습니다.
일반적으로 딥러닝(Deep Learning)이라고 하면 2개 이상의 은닉층을 가진 신경망을 말합니다.
3. 출력층
출력층은 가장 마지막에 위치한 층이며 은닉층 연산을 마친 값이 출력되는 층입니다.
출력층이 아래와 같이 구성됩니다.
▪ 이진 분류(Binary Classification)
활성화 함수로는 시그모이드(Sigmoid) 함수를 사용하며 출력층의 노드 수는
1로 설정합니다. 출력되는 값이 0과 1 사이의 확률값이 되도록 합니다.
▪ 다중 분류(Multi-class Classification)
활성화 함수로는 소프트맥스(Softmax) 함수를 사용하며 출력층의 노드 수는
레이블의 클래스(Class) 수와 동일하게 설정합니다.
▪ 회귀(Regression)
일반적으로는 활성화 함수를 지정해주지 않으며 출력층의 노드 수는 출력값의
특성(Feature) 수와 동일하게 설정합니다.
💡 활성화 함수
sigmoid
▪ x가 증가할 수록 1에 수렴하고, x가 감소 하면 0에 수렴한다.
▪ 이진 분류의 경우 사용한다.
softmax
▪ 다중클래스(multi-class)분류
▪ 출력된 값을 확률로 바꾼다.
Relu
초창기 인공 신경망의 은닉층에 많이 사용된 활성화 함수는 시그모이드 함수였다.
하지만 이 함수에는 단점이 있었는데, 양쪽 끝으로 갈수록 그래프가 누워있기 때문에
올바른 출력을 만드는데 신속하게 대응하지 못했다.
특히 층이 많은 신경망일수록 그 효과가 누적되어 학습을 더 어렵게 만들었다.
이를 개선하기 위해 제안된 활성화 함수가 렐루(RELU) 함수이다.
렐루 함수는 X가 0보다 크면 X를, 0보다 작으면 0을 출려한다.
특히 이미지 처리에서 좋은 성능을 낸다고 알려져있다.
💡 손실 함수
Binary Crossentropy
1. Binary classification. 즉, 클래스가 두 개인 이진 분류 문제에서 사용
2. label이 0 또는 1을 값으로 가질 때 사용
3. 모델의 마지막 레이어의 활성화 함수는 sigmoid
Categorical Crossentropy
1. Multi-class classification 즉 클래스가 여러 개인 다중 분류 문제에서 사용
2. label이 원-핫 인코딩 된 형태.
즉 label이 class를 나타내는 one-hot vector를 값으로 가질 때 사용.
예를 들면3-class classification 문제에서 label이 [1, 0, 0] 또는 [0, 1, 0]
또는 [0, 0, 1]을 값으로 가질 때 사용
3. 모델의 마지막 레이어의 활성화 함수는 softmax
Sparse Categorical Crossentropy
1. Multi-class classification. 즉, 클래스가 여러 개인 다중 분류 문제에서 사용
2. label이 정수 인코딩 된 형태 즉 label이 class index를 값으로 가질 때 사용
ex. 3-class classification 문제에서 label이 0또는 1또는 2를 가질 때 사용
3. 모델의 마지막 레이어의 활성화 함수는 softmax
🔎 인공 신경망 모델 만들기(실습)
MNIST 데이터셋으로 실습을 진행하였다.
데이터 불러오기 및 train/val 분리
from tensorflow import keras
from sklearn.model_selection import train_test_split
# MNSIT 데이터셋 가져오기
(train_input, train_target),(test_input,test_target) = keras.datasets.fashion_mnist.load_data()
# 정규화(0~1 사이 값)
# 255 : 픽셀값.
train_scaled = train_input / 255
# 2차원 → 1차원
train_scaled = train_scaled.reshape(-1,28*28)
# train/val 분리
# 인공 신경망에서는 교차 검증을 잘 사용하지 않고 검증 세트를 별도로 덜어내어 사용
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size=0.2, random_state=42
)
모델생성 방법1
# 은닉층 생성
dense1 = keras.layers.Dense(100, activation='sigmoid', input_shape=(784,))
# 출력층 생성
dense2 = keras.layers.Dense(10, activation='softmax', input_shape=(784,))
# 신경망 모델 생성
model = model.Sequential([dense1,dense2])
모델생성 방법2
model2 = keras.Sequential([
keras.layers.Dense(100, activation='sigmoid', input_shape=(784,), name='hidden'),
keras.layers.Dense(10, activation='softmax', name='output')
], name='패션 MNIST 모델')
모델생성 방법3
가장 깔끔하고 유지 보수가 편할 것 같다.
model3 = keras.Sequential()
model3.add(keras.layers.Dense(100, activation='sigmoid', input_shape=(784,)))
model3.add(keras.layers.Dense(10, activation='softmax'))
생성한 model에 대한 정보
model.summary()
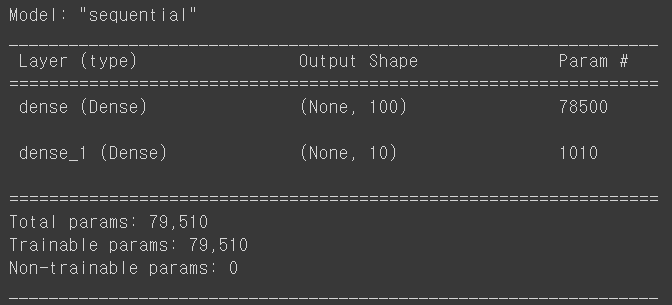
출력 결과를 보면 Output Shape에 (None,100)이라고 되어있다.
첫 번째 차원은 샘플의 개수를 나타낸다.
샘플 개수가 아직 정의되어 있지 않기 때문에 None이다.
keras 모델의 fit() 메서드에 훈련 데이터를 주입하면 이 데이터를 한 번에 모두 사용하지
않고 잘게 나누어 여러 번에 걸쳐 경사 하강법 단계를 수행한다. (미니배치 경사 하강법)
keras의 기본 미니배치 크기는 32개인데, 이 값은 fit() 메서드에서 batch_size 매개변수로
바꿀 수 있다. 따라서 샘플 개수를 고정하지 않고 어떤 배치 크기에도 유연하게 대응할 수
있도록 None으로 설정한 것이다.
마지막으로는 모델의 파라미터 개수가 출력된다.
입력층의 뉴런 개수(784) * 가중치(100개) + 절편(100개) = 78500개
은닉층의 뉴런 개수(100) * 가중치(10개) + 절편(10개) = 1010개
나머지 설정 및 성능 확인
# model compile
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
# model 학습
model.fit(train_scaled, train_target, epochs=5)
# val Set에서 model성능 확인
model.evaluate(val_scaled, val_target)
