CNN을 활용한 이미지 분류
in Deep Learning on CNN
💡 CNN 모델링 실습
MNIST 데이터 로드
from tensorflow import keras
from sklearn.model_selection import train_test_split
(train_input, train_target), (test_input,test_target) = \
keras.datasets.fashion_mnist.load_data()
# Conv2D는 사용하기 위해서 깊이 차원을 추가해줘야 한다.
train_scaled = train_input.reshape(-1,28,28,1)/255
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train
모델링
# Sequential() 통한 모델 객체 생성
model = keras.Sequential()
#〓〓〓〓〓〓〓〓〓〓〓 첫 번째 합성곱-풀링 층 〓〓〓〓〓〓〓〓〓〓〓#
# Conv2D
model.add(keras.layers.Conv2D(
32,
kernel_size=3,
activation='relu',
padding='same',
input_shape=(28,28,1)
))
# Pooling
model.add(keras.layers.MaxPooling2D(2, strides=2, padding='valid'))
#〓〓〓〓〓〓〓〓〓〓〓 두 번째 합성곱-풀링 층 〓〓〓〓〓〓〓〓〓〓〓#
model.add(keras.layers.Conv2D(
64,
kernel_size=3,
activation='relu',
padding='same'
))
model.add(keras.layers.MaxPooling2D(2, strides=2, padding='valid'))
#〓〓〓〓〓〓〓〓〓〓 3차원 특성 맵을 1차원으로 〓〓〓〓〓〓〓〓〓〓#
# Flatten
model.add(keras.layers.Flatten())
# 은닉층
model.add(keras.layers.Dense(100,activation='relu'))
# Dropout 은닉층의 과대적합을 예방.
model.add(keras.layers.Dropout(0.4))
# 출력층
model.add(keras.layers.Dense(10, activation='softmax'))
# 모델 상세
model.summary()
아래는 summary 출력값이다.
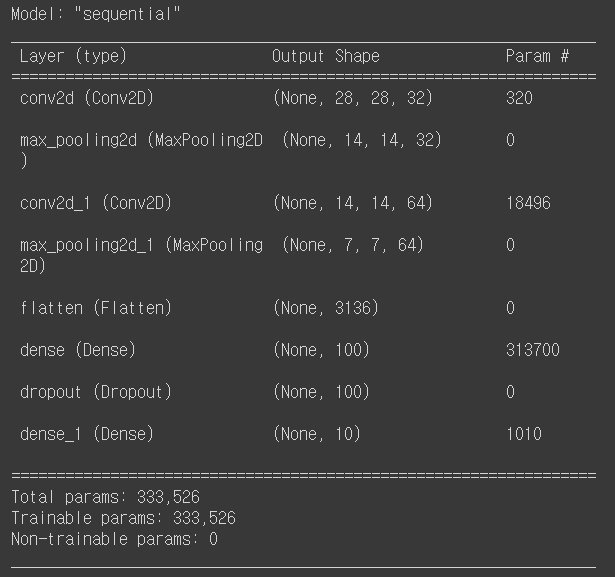
- 첫 번째 합성곱층
- 필터가 : 32개
- 필터 크기 : (3,3,1)
- 절편 : 32개
Param = (3x3x1x32) + 32 = 320
- 두 번째 합성곱층
- 필터가 : 64개
- 필터 크기 : (3,3,32)
- 절편 : 64개
Param = (3x3x32x64) + 64 = 18496
- Flatten
Output Shape : 7x7x62 = (3136,)
은닉층
Param = 3136 x 10 + 100 = 313700
출력층
Parma = 100 x 10 + 10 = 1010
층의 구성 시각화
show_shapes=True 로 지정해주지 않으면 input,output은 출력되지 않는다.
to_file = "name.확장자" 를 지정해주면 출력 이미지를 저장할 수 있다.
keras.utils.plot_model(model, show_shapes=True)
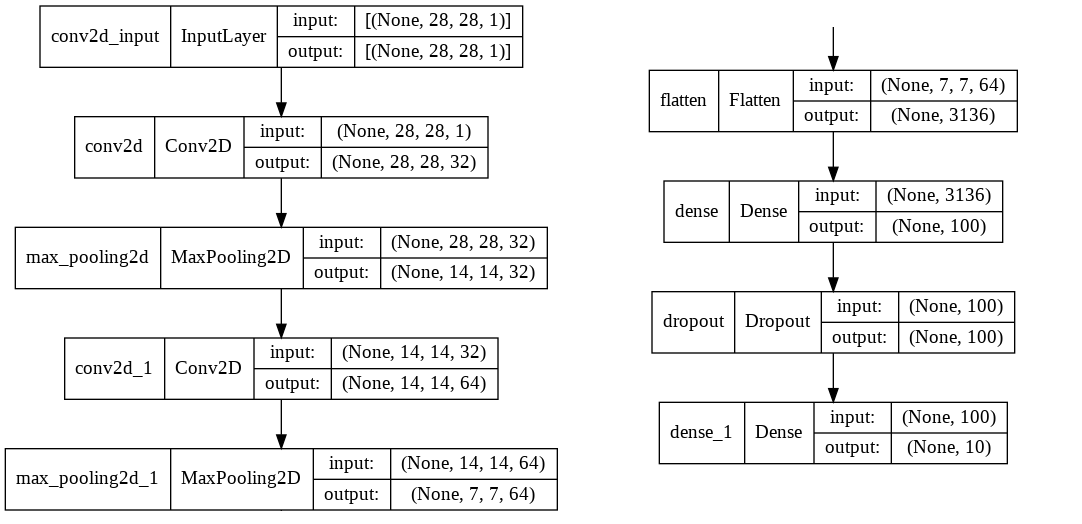
모델 컴파일 & 훈련
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics='accuracy'
)
# 콜백
checkpoint_cb = keras.callbacks.ModelCheckpoint(
'best-cnn-model.h5',
save_best_only = True
)
# 조기 종료
early_stopping_cb = keras.callbacks.EarlyStopping(
patience=2,
restore_best_weights=True
)
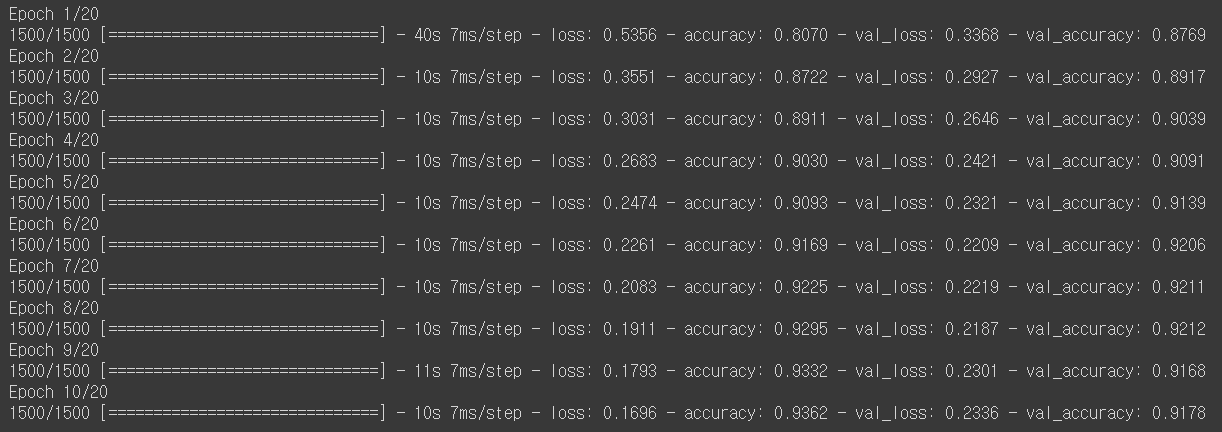
# 모델 훈련
history = model.fit(train_scaled, train_target, epochs=20,
validation_data=(val_scaled,val_target),
callbacks = [checkpoint_cb, early_stopping_cb])
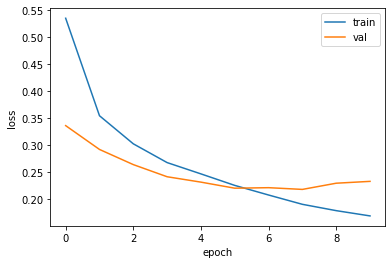
손실 곡선 시각화
import matplotlib.pyplot as plt
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train','val'])
plt.show()
8번 에포크와 결과가 같다는걸 확인할 수 있다.
test_input 이미지 예측해보기
# test set 성능 측정
test_scaled = test_input.reshape(-1,28,28,1)/255
model.evaluate(test_scaled,test_target)
# test_scaled 예측
test_pred = model.predict(test_scaled)
# 일부만 시각화
fig,axs = plt.subplots(2,2,figsize=(9,9))
for i in range(2):
axs[i,0].imshow(test_input[i].reshape(28,28), cmap='gray_r')
axs[i,1].bar(range(1,11),test_pred[i])
plt.show()

추가적으로 predict() 에 샘플 하나를 전달할 때 슬라이싱을 사용해야한다.
keras에서 fit(), predict(), evaluate() 메서드는 모두 입력의 첫 번째 차원이
배치 차원일 것으로 기대한다. 따라서 샘플 하나를 전달할 때 (28,28,1)이 아니라
(1,28,28,1) 크기를 전달해야 한다. 배열 슬라이싱은 인덱싱과 다르게 선택된 원소가
하나이더라도 전체 차원이 유지되어 (1,28,28,1) 크기를 만든다.
아래 사진처럼 슬라이싱 했을 때와 아닐 때 shape의 차이를 확인할 수 있었다.

