JPA란?
왜 JPA인가?
이런 경우를 생각해보자. 기존에는 아래와 같이 Vo설계를 했을 것이다.
public class Member {
private String name;
private String birth;
}
INSERT INTO MEMBER (NAME, BIRTH)
VALUES (:name, :birth)
그러나 기획이 바뀌게 되어 Member에 주소를 추가하게 된다면??
자바 클래스와 SQL을 수정해야 한다.
public class Member {
private String name;
private String birth;
private String address;
}
INSERT INTO MEMBER (NAME, BIRTH, ADDRESS)
VALUES (:name, :birth, :address)
이렇게 JPA를 쓰지 않으면 SQL에 의존적이 개발을 피하기가 어렵다.
객체를 자바 컬렉션에 저장하듯이 DB에 저장할 수는 없을까?🧐
관계형 데이터베이스를 쓰는 현재에는 SQL에 의존적인 개발을 피하기 어렵다.
그리고 객체와 관계형 데이터베이스는 패러다임이 일치하지 않는다.
객체 지형 프로그래밍은 추상화, 캡슐화, 정보은닉, 상속, 다형성 등
시스템의 복잡성을 제어할 수 있는 다양한 장치들을 제공한다.
객체와 관계형 데이터베이스의 차이
| 객체 | RDBMS | |
|---|---|---|
| 상속 | O | X |
| 연관관계 | 참조(getXxx) | 외래키(FK) |
| 데이터 타입 | ||
| 데이터 식별 방법 |
JPA란?
Java Persistence API
✓ 자바 진영의 ORM 기술 표준.
✓ 인터페이스의 모음
✓ JPA 2.1 표준 명세를 구현한 3가지 구현체 : 하이버네이트, EclipseLink, DataNucleus
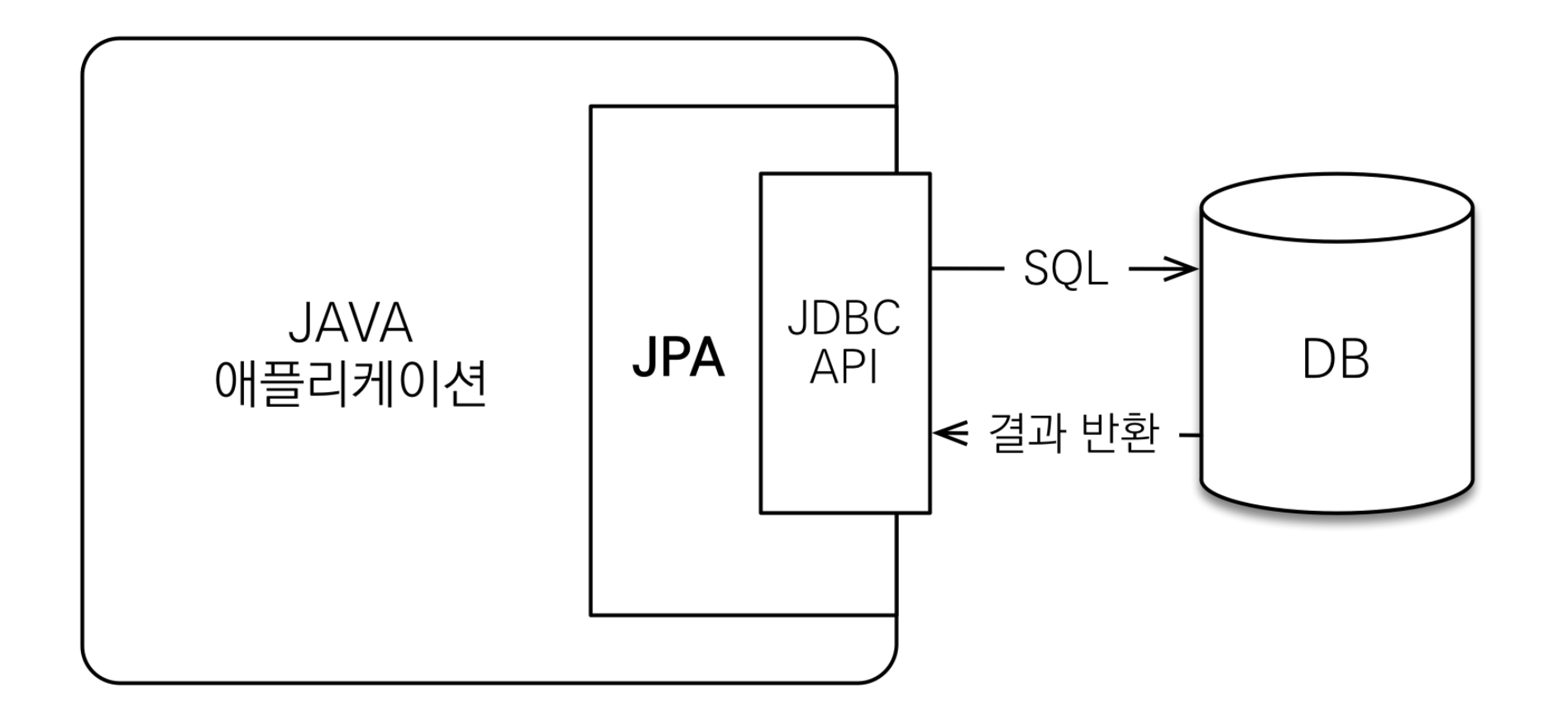
JPA 동작 원리
JPA는 애플리케이션과 JDBC 사이에서 동작한다.
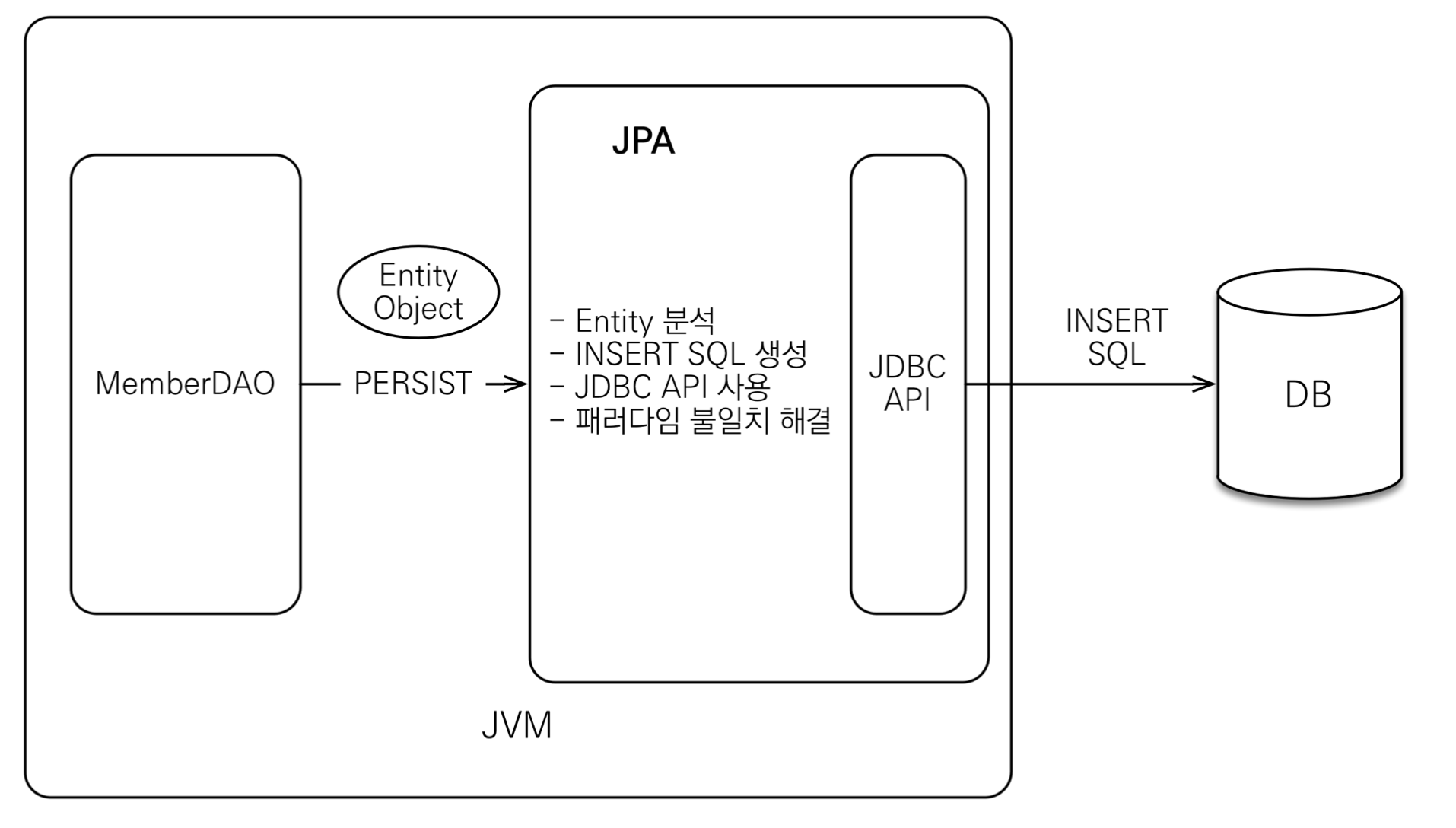
저장
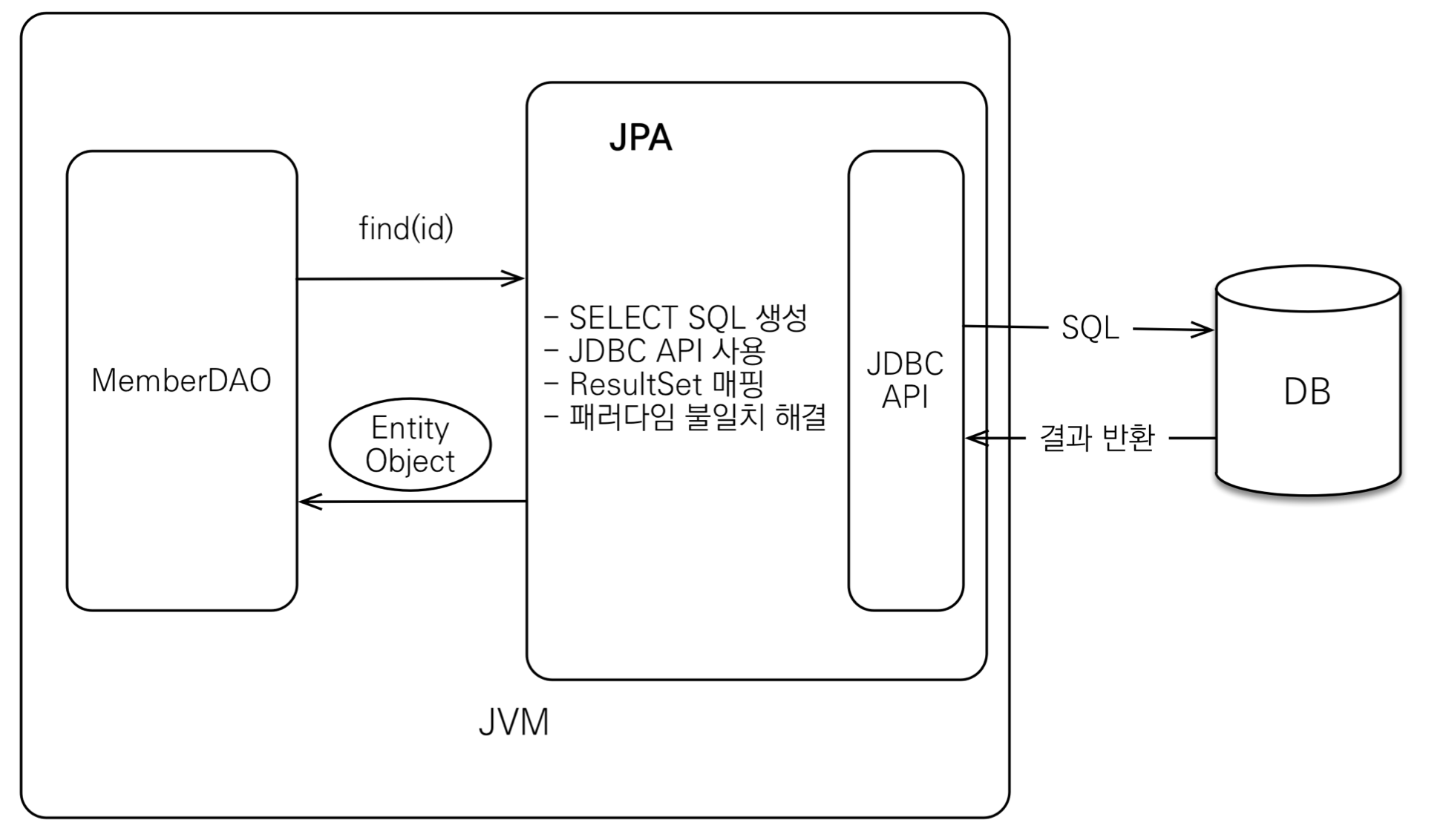
조회
JPA를 왜 사용해야 하는가?
1.SQL 중심적인 개발에서 객체 중심으로 개발
2.생산성
• 저장 : jpa.persist(member);
• 조회 : Member member = jpa.find(memberId);
• 수정 : member.setName(“변경할 이름”);
• 삭제 : jpa.remove(member);
3. 유지보수 (필드만 추가하면 된다.)
개발자가 고민해야 하는 포인트가 줄어든다.
기존에는 필드가 추가 및 삭제 되는 경우 모든 SQL을 수정해야 했다.
하지만 JPA를 사용하면 필드만 추가하면 되기 때문에 개발자가 SQL문까지
수정할 필요가 없다. SQL은 JPA가 처리해준다.
RDBMS와 객체의 불일치 패러다임 해소.
• JPA 상속
• JPA와 연관관계, 객체 그래프 탐색
• JPA와 비교하기(연산자)
성능 최적화 (캐싱, 동일성 보장, 버퍼링)
• 1차 캐시와 동일성(identity) 보장
• 트랜잭션을 지원하는 쓰기 지연(transactional write-behind)
• 지연 로딩(Lazy Loading)
지연 로딩, 즉시 로딩
• 지연 로딩 : 객체가 실제 사용될 때 로딩(쿼리가 더 많이 나간다.)
• 즉시 로딩 : JOIN SQL로 한 번에 연관된 객체까지 미리 조회
