SQL 튜닝 1장 - MySQL과 MariaDB 개요
in SQL
MySQL과 MariaDB 개요
구조적 차이
▶︎ 오라클 DB
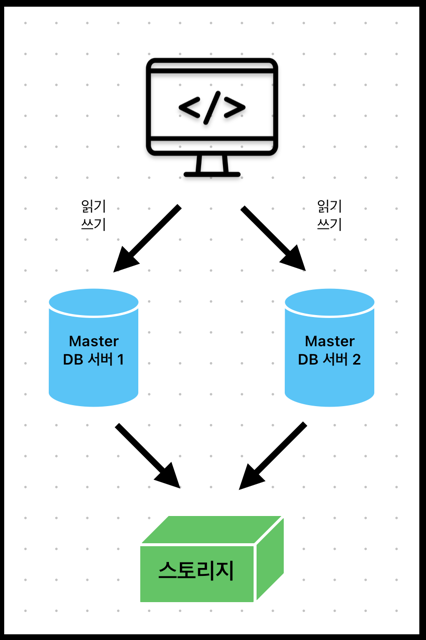
오라클의 경우에는 아래의 이미지와 같이,
통합된 스토리지 하나를 공유(shared everything)하는 방식을 사용한다.
이렇게 공유 스토리지를 사용하기 때문에 사용자가 어느 DB 서버에 접속하여 sql 문을 수행하여도
같은 결과를 출력하거나 동일한 구문(SELECT, INSERT, DELETE, UPDATE)을 처리할 수 있다.
▶︎ MySQL DB
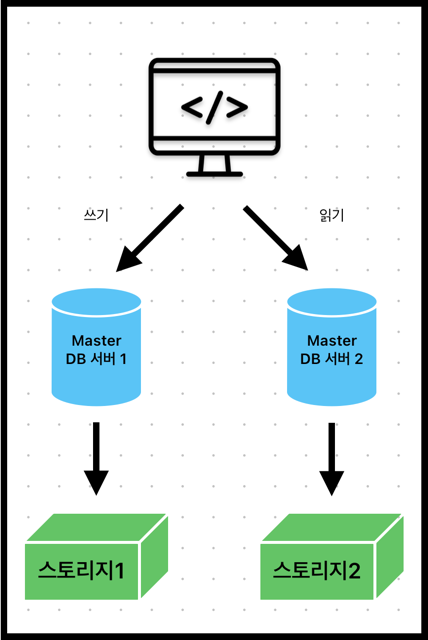
MySQL은 물리적인 DB 서버마다 독립적으로 스토리지를 할당(shared nothing)하여 구성한다.
MySQL은 독립적인 스토리지 할당에 기반을 두는 만큼 이중화를 위한 클러스터나 복제 구성으로
운영하더라도, 보통은 master-slave 구조가 대부분이다.
master 노드는 쓰기/읽기 처리를 모두 수행할 수 있고 slave 노드는 읽기 처리만 수행할 수 있다.
쿼리 오프로딩
DB 서버의 트랜잭션에서 쓰기 트랜잭션과 읽기 트랜잭션을 분리하여 DB 처리량을 증가시키는
성능 향상 기법.
- 쓰기 트랜잭션 : UPDATE, INSERT, DELETE
- 읽기 트랜잭션 : SELECT
지원 기능 차이
▶︎ 오라클 DB
정렬 병합 조인
해시 조인
▶︎ MySQL DB
중첩 루프 조인 알고리즘
필요한 DBMS를 설정해 사요할 수 있다.
상대적으로 낮은 메모리를 사용한다.
조인 알고리즘
중첩 루프 조인 (NESTED LOOP JOIN)
▶︎ [ NESTED LOOP JOIN 이란? ]
두 개 이상의 테이블에서 하나의 집합을 기준으로 상대방 Row와 순차적으로 결합하여 결과를 조합하는 방식
- 조인해야 할 데이터가 많지 않은 경우에 유용하게 사용된다.
- 순차적으로 처리하며 Random Access 방식으로 데이터를 읽는다.
- Driven Table에는 조인을 위한 인덱스가 생성되어 있어야 한다.
실행속도 = 선행 테이블 사이즈 x 후행 테이블 접근횟수
Loop 개수를 줄이기 위해 조인에 참여하는 테이블 중 Row수가 적은 쪽을 Driving으로 설정하고,
Inner 테이블의 연결고리를 결합인덱스를 이용해 최적화해야 한다.
▶︎ [ 동작 방식 ]
- Driving Table에서 조건을 만족하는 첫 번째 행을 찾는다.
- Driven Table의 인덱스에서 Driving Table의 조인 키가 있는지 찾는다.
- 인덱스에서 추출한 레코드 식별자를 이용하여 Driven Table에 access
- Driven Table에 주어지 조건까지 만족하면 해당 행을
추출 버퍼에 넣는다.
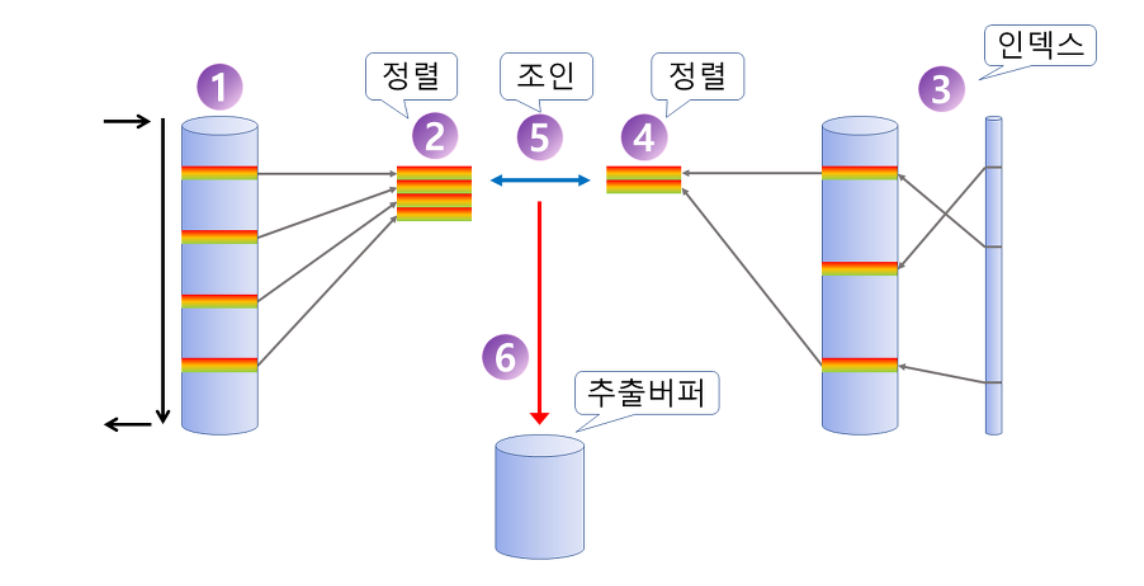
정렬 병합 조인 (SORT MERGEO JOIN)
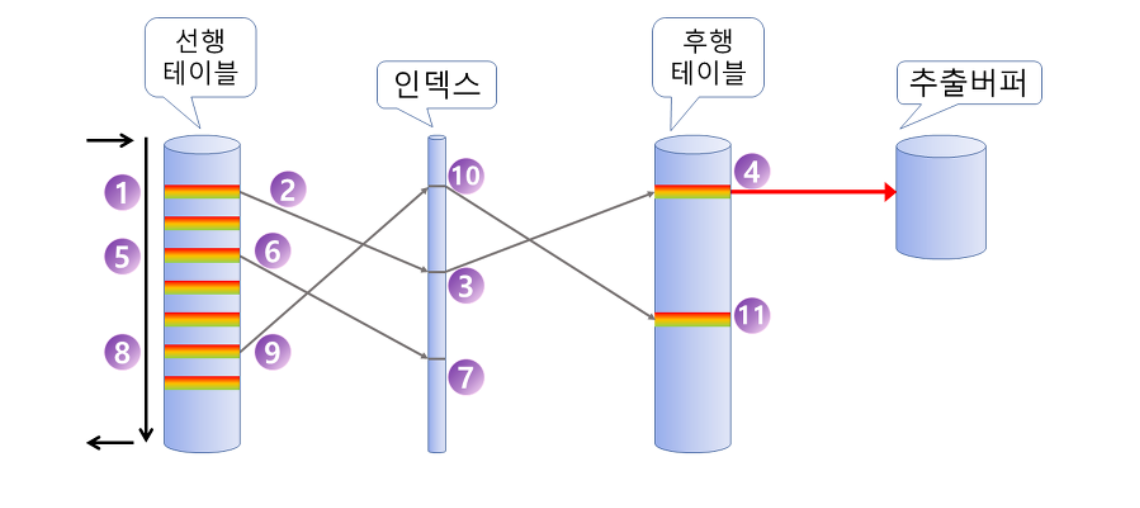
▶︎ [ SORT MERGE JOIN 이란? ]
양쪽 테이블을 각각 Access 하여 그 결과를 정렬하고 그 정렬한 결과를 차례로 Scan 해 나가면서 Merge를 하는 방식
- 조회의 범위가 많을 때 주로 사용한다.
- 주로 조인 조건 칼럼에 인덱스가 없거나, 출력해야 할 결과 값이 많을 때 사용한다.
- 연결 고리에 인덱스가 전혀 없는 경우 사용한다.
- 조인 조건으로 <, >, <=, >=와 같은 범위 비교 연산자가 사용된 경우
▶︎ [ 동작 방식 ]
- 각 테이블에 대해 동시에 독립적으로 데이터를 먼저 읽어 들인다.
- 읽혀진 각 테이블의 데이터를 조인을 위한 연결고리에 대하여 정렬을 수행한다.
- 정렬이 모두 끝난 후에 조인 작업이 수행한다.
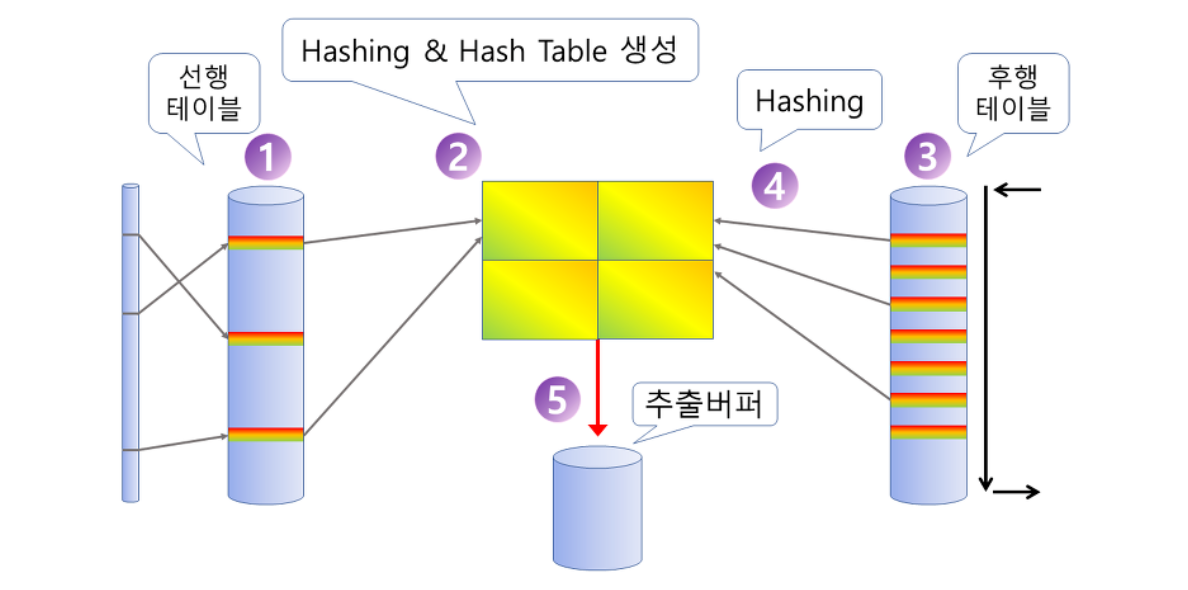
해시 조인 (HASH JOIN)
▶︎ [ HASH JOIN 이란? ]
HASH 조인은 조인될 두 테이블 중 하나를 해시 테이블로 선정하여 조인될 테이블의 조인 키 값을 해시 알고리즘으로 비교하여 매치되는 결과값을 얻는 방식
- JOIN 컬럼에 적당한 인덱스가 없어 NL JOIN이 비효율적일 때
- JOIN Access량이 많아 Random Access 부하가 심하여 NL JOIN이 비효율적일 때
- Sort Merge Join을 하기에는 두 테이블이 너무 커 Sort 부하가 심할 때
- 수행빈도가 낮고 쿼리 수행 시간이 오래 걸리는 대용량 테이블을 JOIN 할 때
▶︎ [ 동작방식 ]
- 선행 테이블에서 주어진 조건을 만족하는 행을 찾는다. (크기가 작은 테이블을 선행테이블로~)
- 해당 행들에 대해서, 선행 테이블의 조인 키(칼럼)를 기준으로 Hash 함수를 적용하여 해쉬 테이블을 생성
- 후행 테이블에서 주어진 조건을 만족하는 행을 찾는다.
- 해당 행들에 대해서, 후행 테이블에 Hash 함수를 적용하여 선행 테이블의 해쉬 테이블에서 맞는 버킷을 찾음
- JOIN을 수행 & 조인에 성공하면 추출버퍼에 넣는다.
- 후행 테이블의 조건을 만족하는 모든 행에 대해서 3~5번 반복.